2022-10-31
한글 유니코드는 크게 3가지로 구성되어 있습니다.
1.
자모음 유니코드 (ᄀ, ᄁ, ᄉ, ᄊ, ᅡ, ᅤ, ᅪ, ᅰ, ᆨ, ᆸ, ᆹ, ᆭ)
2.
자모음 호환 유니코드 (ㄱ, ㄴ, ㄷ, ㄹ, ㅏ, ㅑ, ㅓ, ㅕ, ㄹ, ㅁ, ㄺ, ㅄ)
3.
음절 유니코드 (가, 나, 밤, 힣)
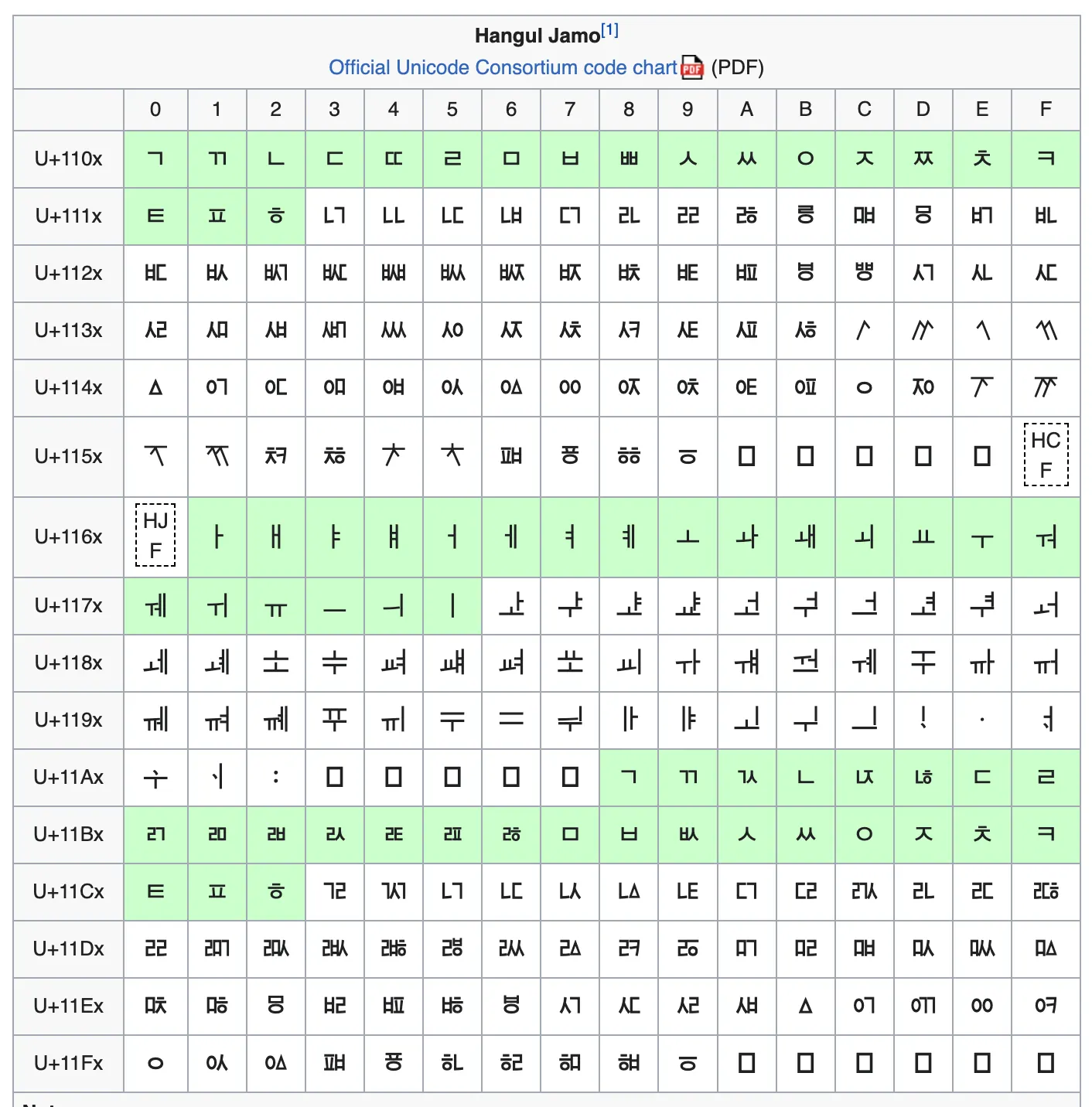
자모음 유니코드

자모음 유니코드는 초성과 중성, 종성으로 이루어진 유니코드 입니다.
아래의 표와 같이 이루어져 있습니다.
같은 기역이더라도 0x1100(ᄀ, 초성)과 0x11A8(ᆨ, 종성)은 다른 글자입니다.
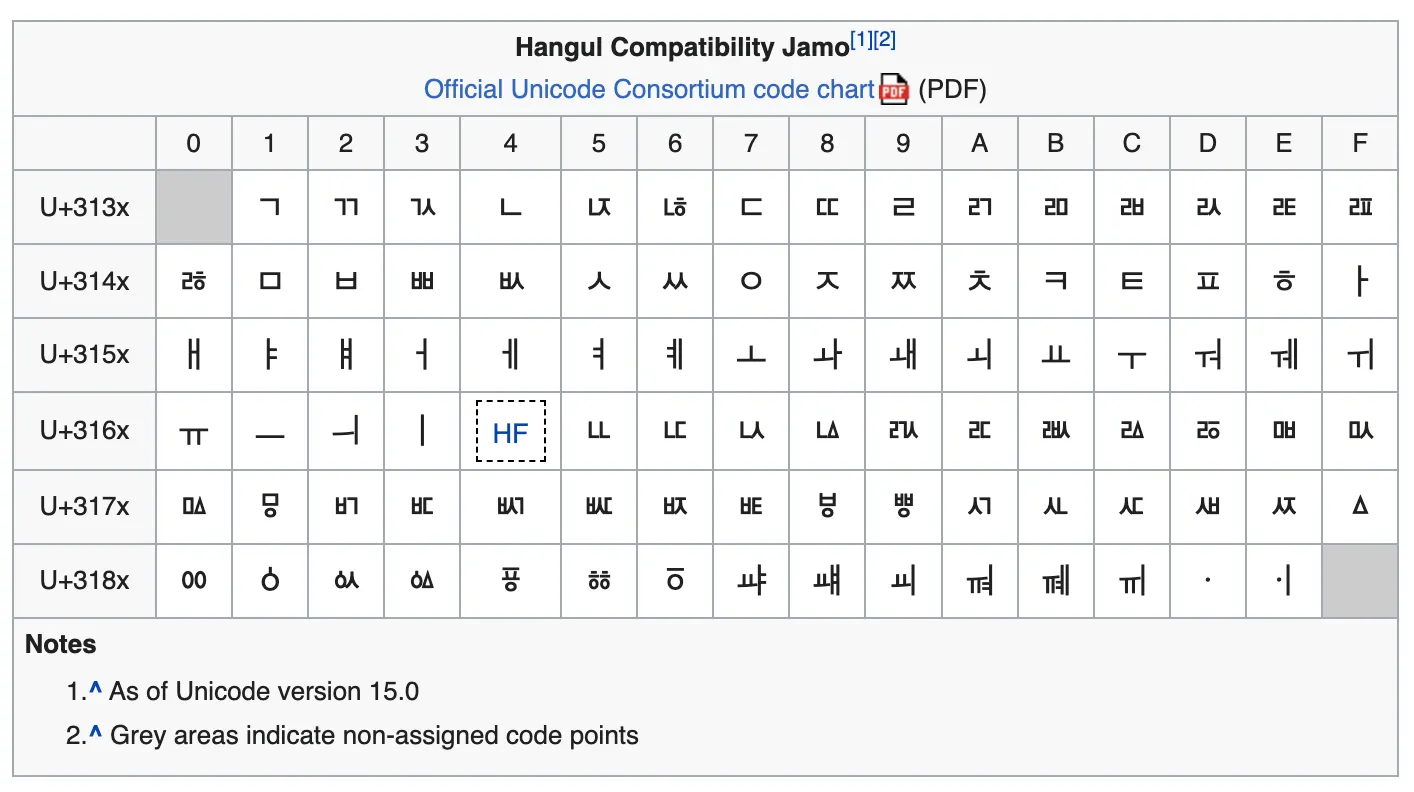
자모음 호환 유니코드
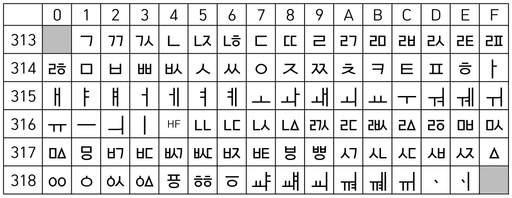
자모음 호환 유니코드는 KS X 1001와 호환되는 유니코드 입니다.

KS X 1001 (구. KS C 5601)은
- 한글과 한자를 상호 변환하기 위한 코드입니다
- 많은 레거시 한글 인코딩에 사용됩니다 (EUC-KR, Microsoft’s Unified Hangul Code (UHC))
- 한글 음절과 CJK 표의문자(한자), 그리스어, 키릴, 일본어 (히라가나, 카타카나) 등을 포함하고 있습니다
자음과 모음으로 구성되어 있습니다.
예를 들면, ㄱ(0x3131) + ㅏ(0x314F) + ㅁ(0x3141) = 감 입니다. 국어시간에 배운 원리랑 동일합니다.
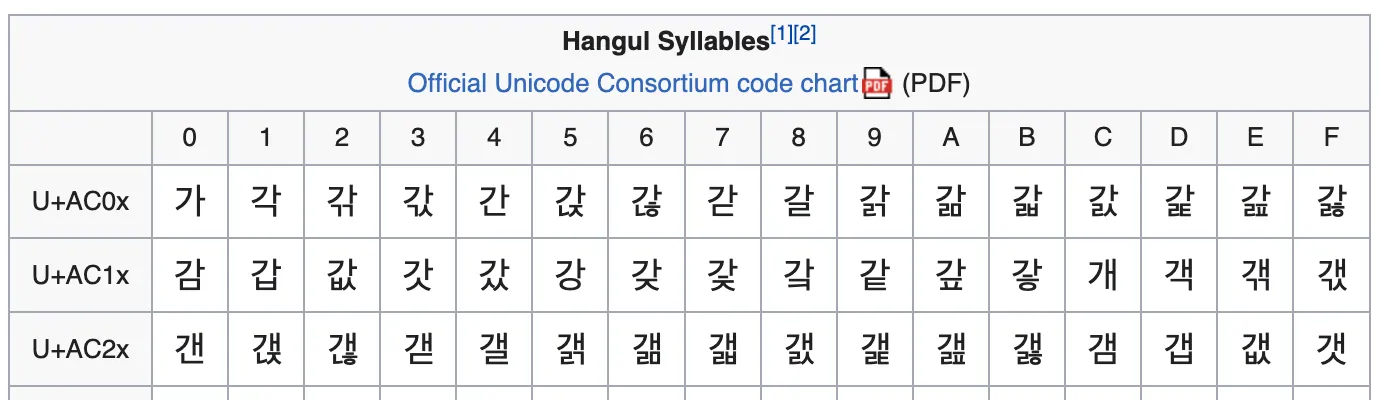
음절 유니코드
음절 유니코드는 현대 한국어의 음절이 유니코드 값으로 매핑된 유니코드 입니다.
이 유니코드 표에 따라서 한국어 음절의 시작은 가이고 끝 음절은 힣 입니다.
그래서 정규표현식에서 한글을 찾을 때 /가-힣/ 으로 찾을 수 있었던 것입니다.