



2022-07-26
Dijkstra 다익스트라 알고리즘 공부한 것을 기록으로 남깁니다.
나동빈님의 유튜브 영상을 참고하였습니다

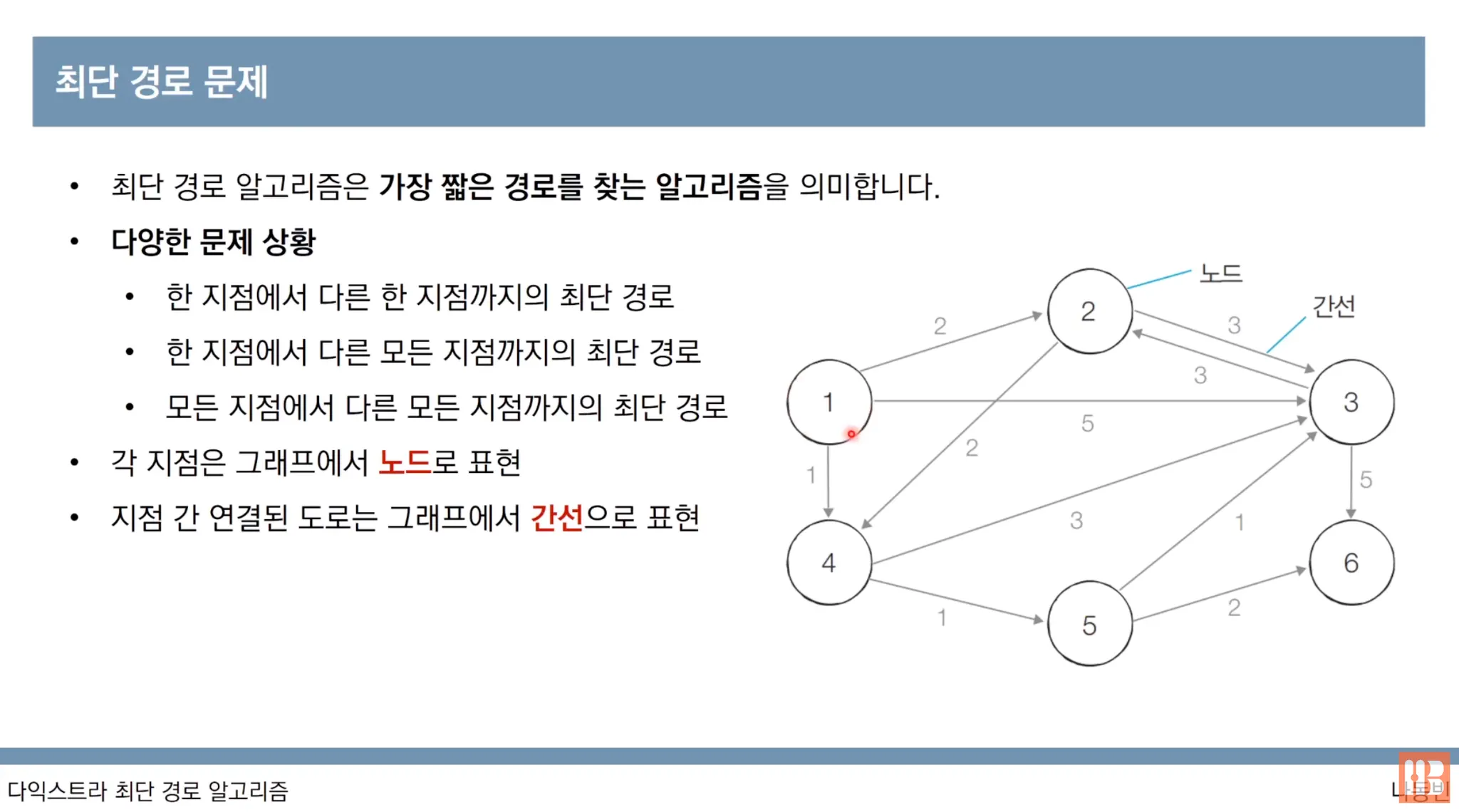
다익스트라 알고리즘 개요

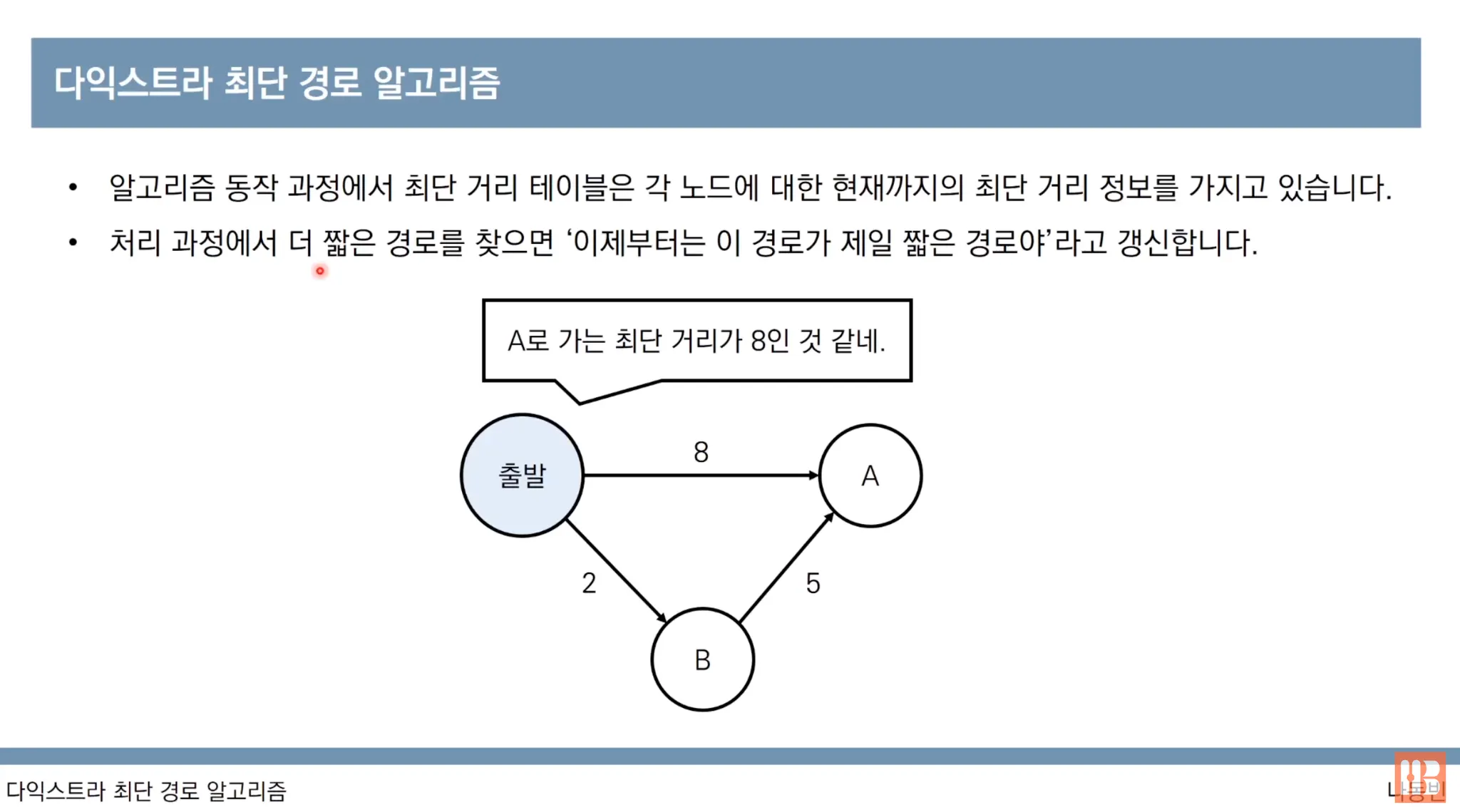
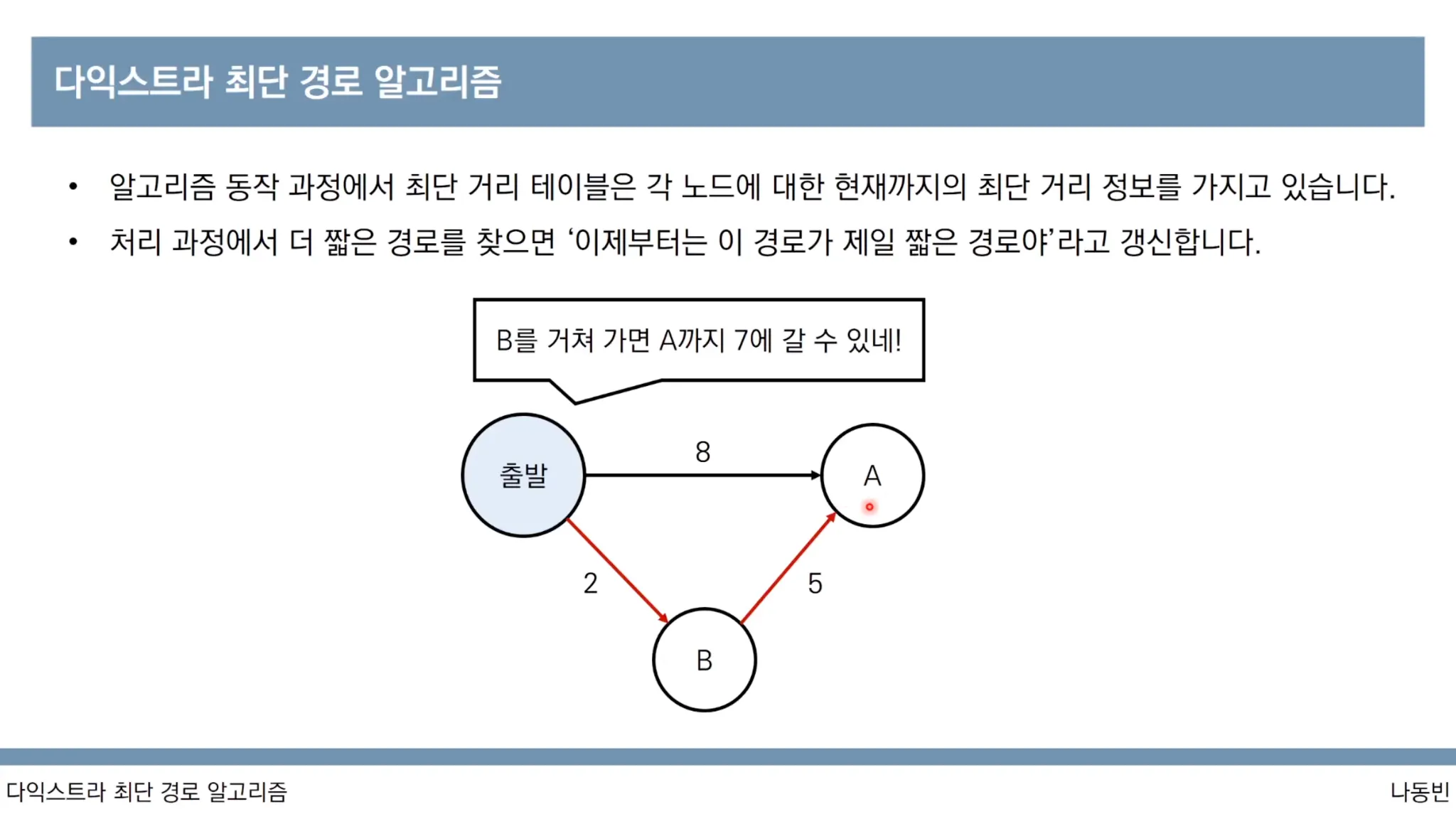
(2) 최단 거리 테이블을 모두 무한(infinite)로 초기화 합니다

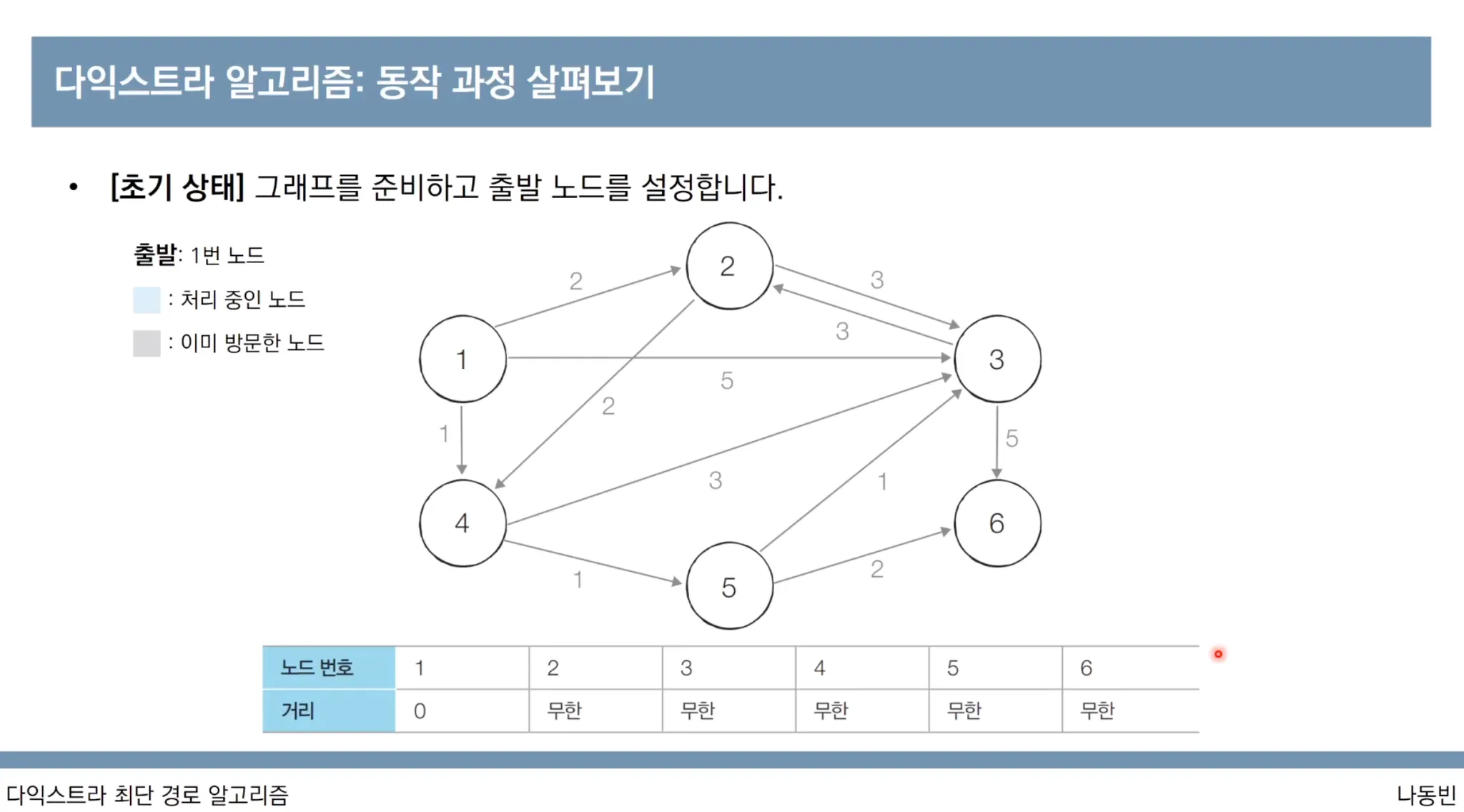
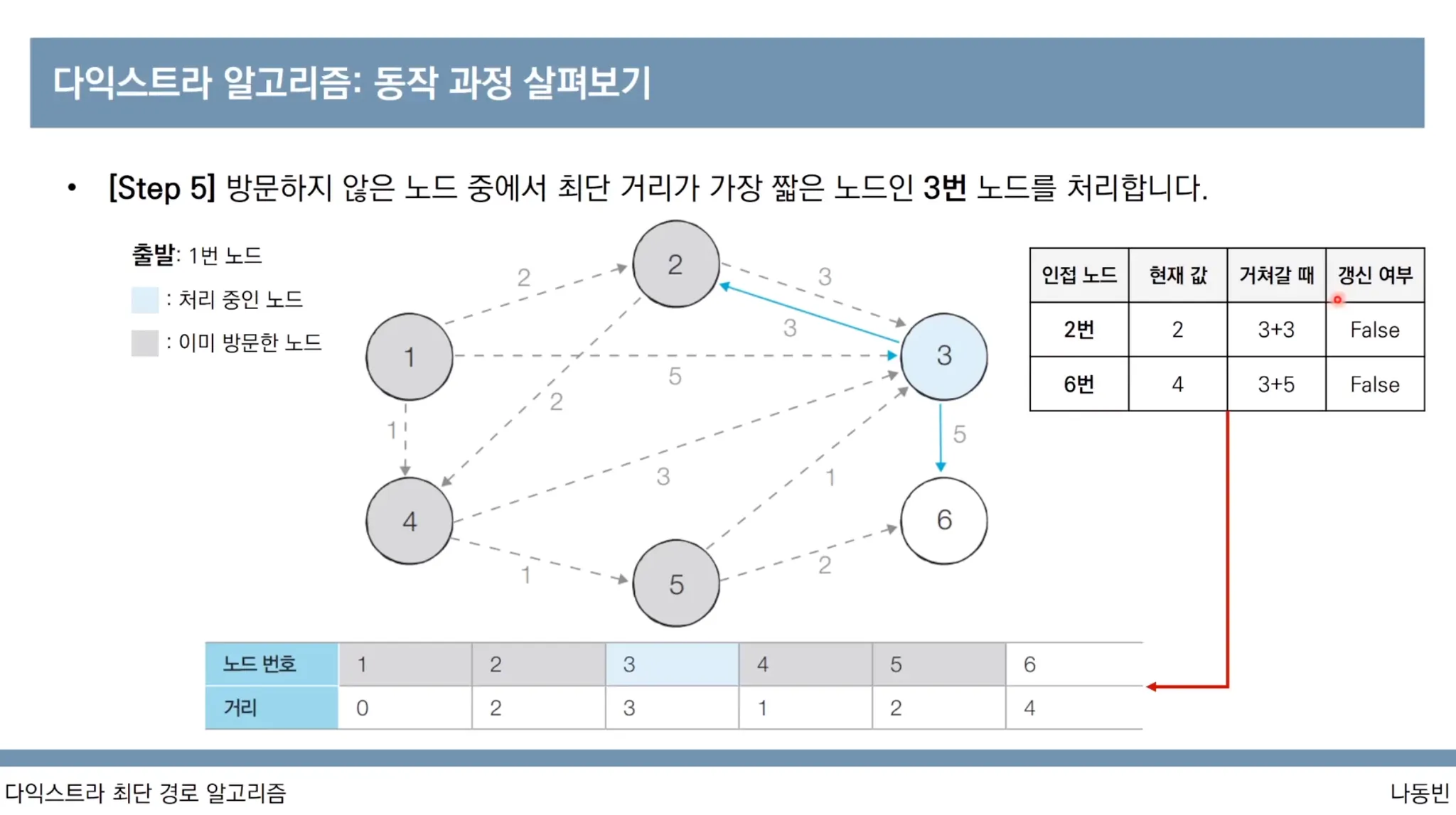
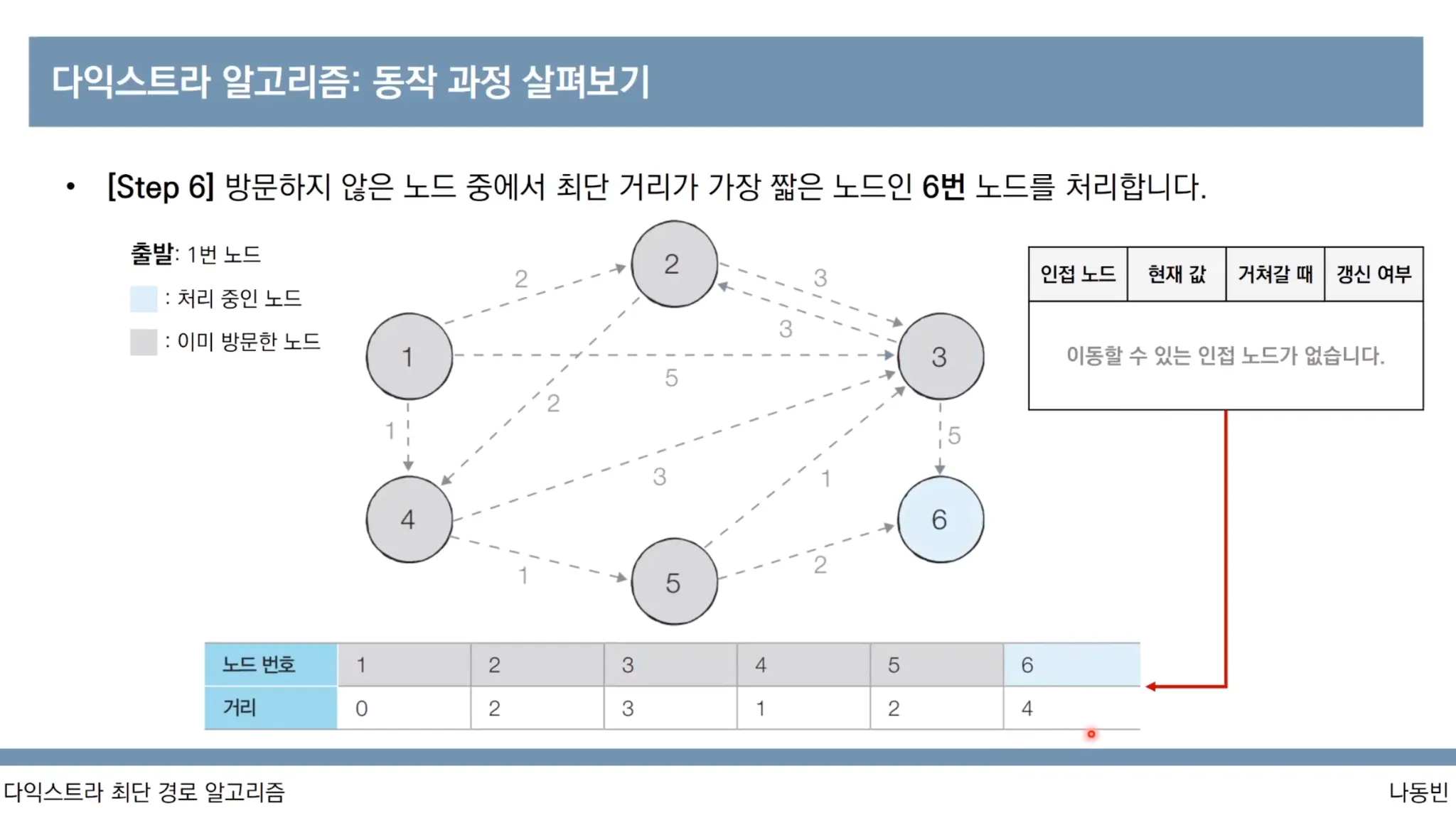
다익스트라 알고리즘 동작과정
1번 노드가 출발 노드입니다
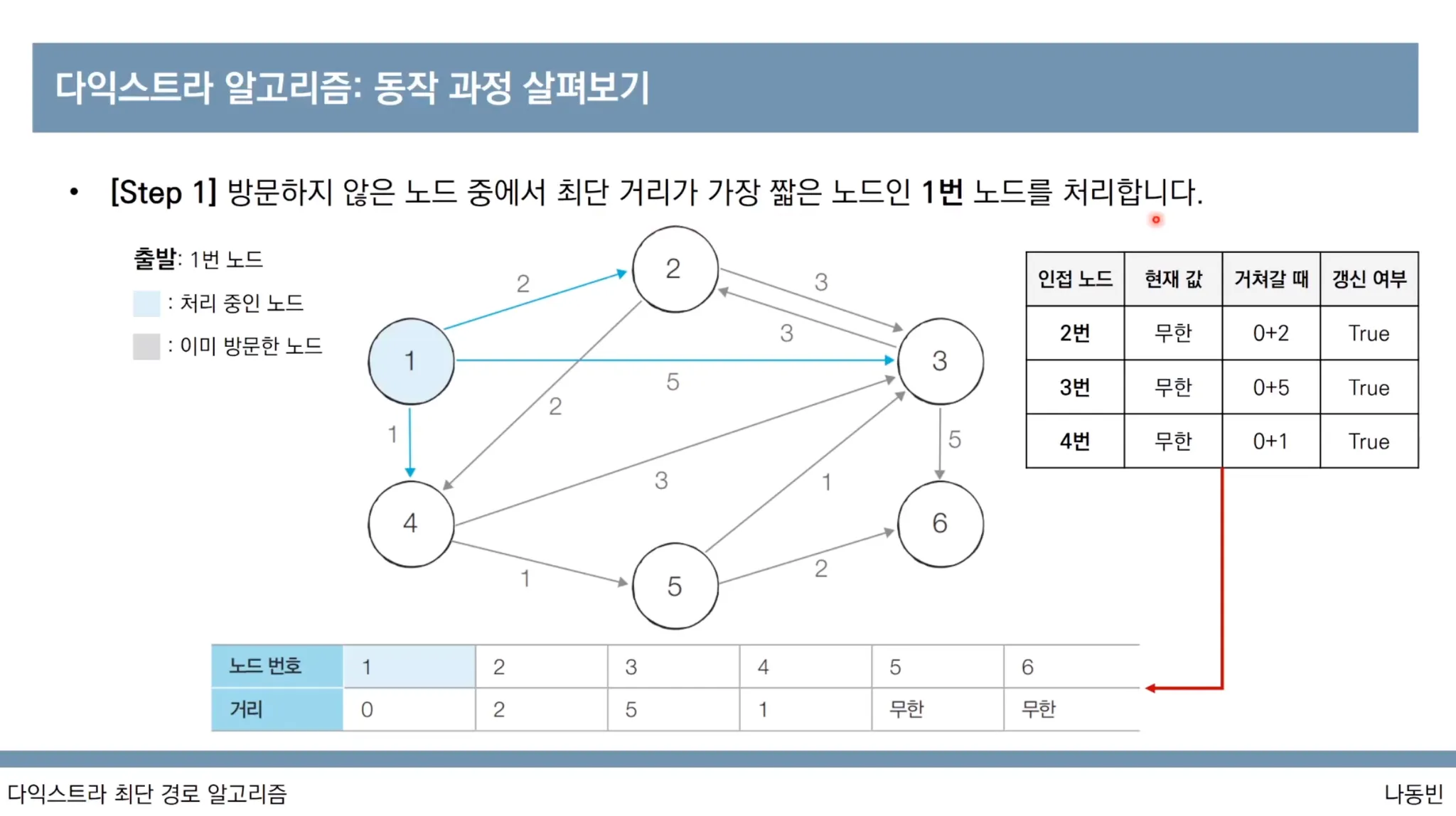
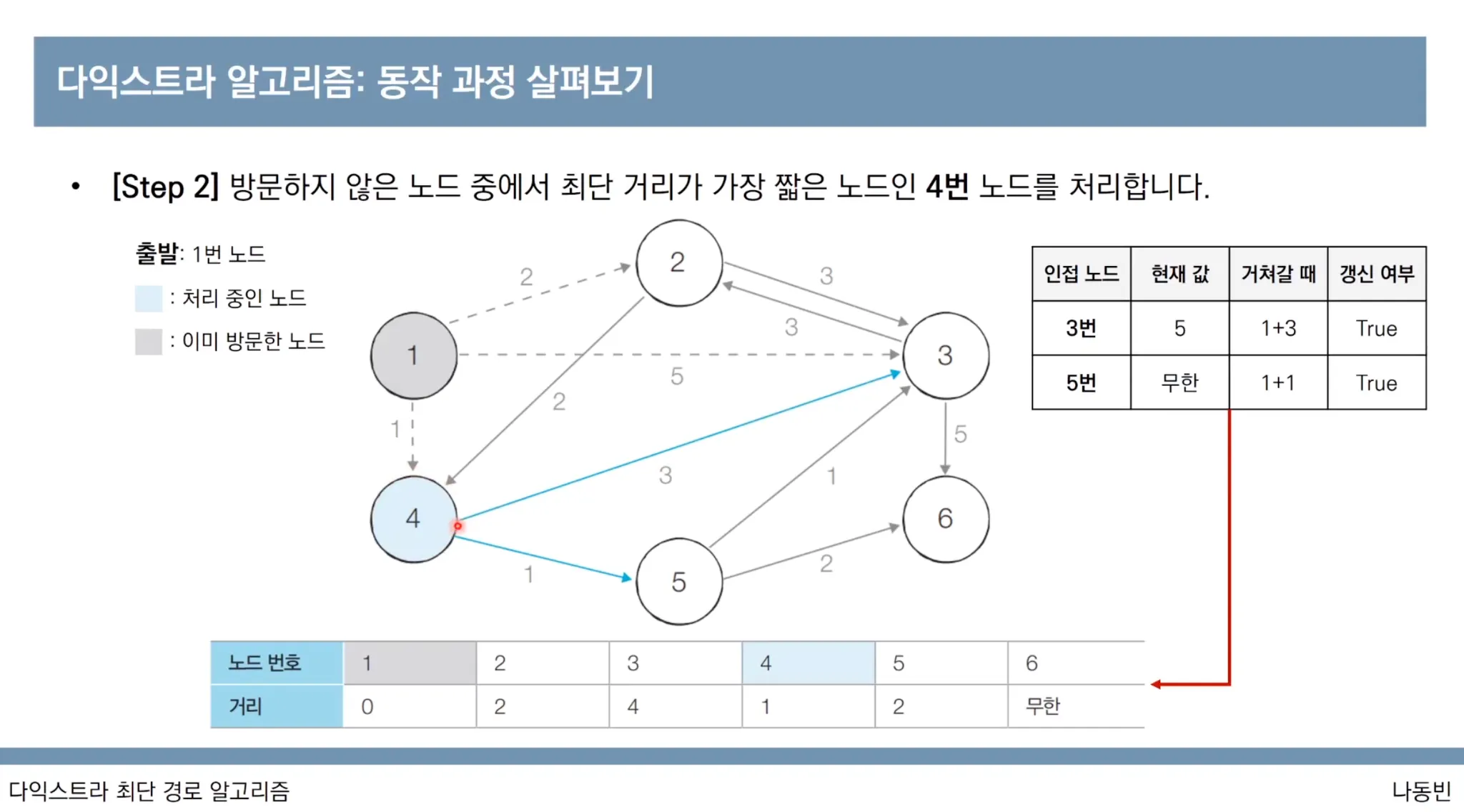
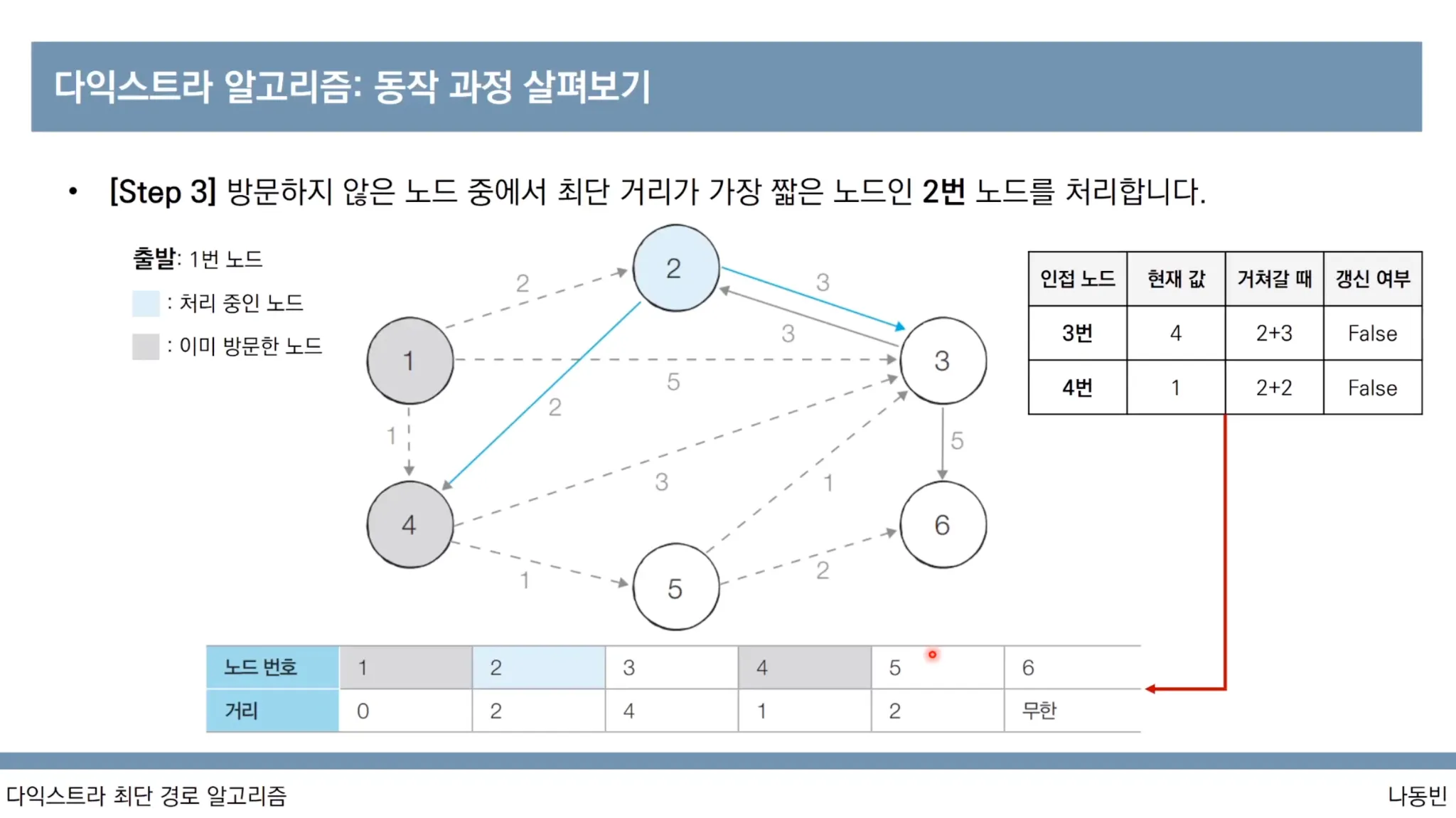
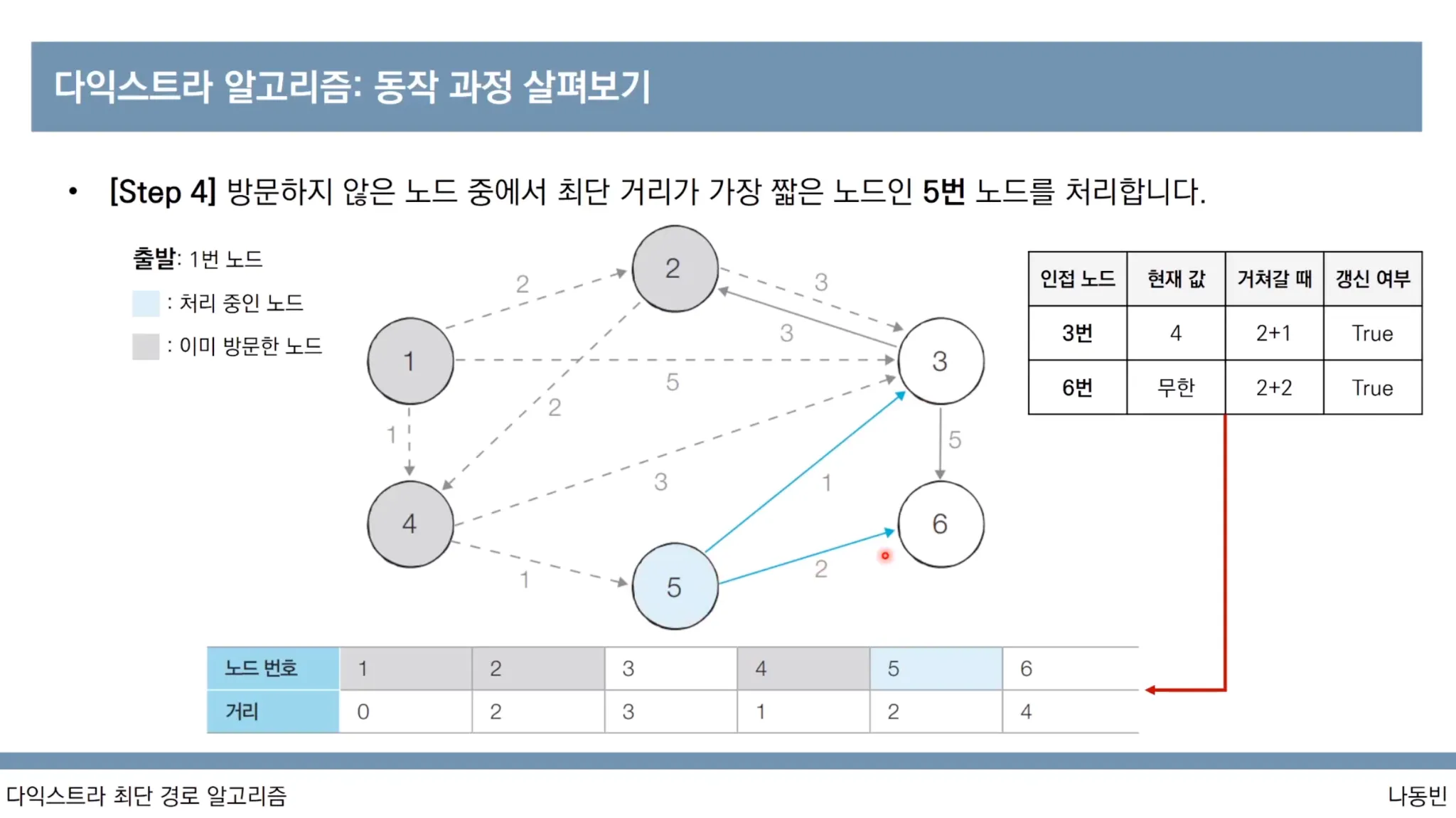
다익스트라 알고리즘 특징


순차 탐색을 통한 다익스트라 알고리즘 Python 코드
import sys
input = sys.stdin.readline
INF = int(1e9)
# 노드의 개수, 간선의 개수 입력받기
n, m = map(int, input().split())
# 시작 노드 번호를 입력받기
start = int(input())
# 각 노드에 연결되어 있는 노드에 대한 정보를 담는 리스트를 만들기
graph = [[] for i in range(n + 1)]
# 방문한 적이 있는지 체크하는 목적의 리스트 만들기
visited = [False] * (n + 1)
# 최단 거리 테이블을 모두 무한으로 초기화
distances = [INF] * (n + 1)
# 모든 간선 정보를 입력받기
for _ in range(m):
a, b, c = map(int, input().split())
# a번 노드에서 b번 노드로 가는 비용이 c
graph[a].append((b, c))
# 방문하지 않은 노드 중에서, 가장 최단 거리가 짧은 노드의 번호를 반환
def get_smallest_node():
min_value = INF
index = 0 # 최단 거리가 가장 짧은 노드 (인덱스)
for i in range(1, n + 1):
if distances[i] < min_value and not visited[i]:
min_value = distances[i]
index = i
return index
def dijkstra(start):
# 시작 노드에 대해서 초기화
distances[start] = 0
visited[start] = True
for j in graph[start]:
distances[j[0]] = j[1]
# 시작 노드를 제외한 전체 n - 1개의 노드에 대해 반복
for i in range(n - 1):
# 현재 최단 거리가 가장 짧은 노드를 꺼내서 방문 처리
now = get_smallest_node()
visited[now] = True
# 현재 노드와 연결된 다른 노드를 확인
for j in graph[now]:
cost = distances[now] + j[1]
# 현재 노드를 거쳐서 다른 노드로 이동하는 거리가 더 짧은 경우
if cost < distances[j[0]]:
distances[j[0]] = cost
# 다익스트라 알고리즘 수행
dijkstra(start)
# 모든 노드로 가기 위한 최단 거리를 출력
for i in range(1, n + 1):
if distances[i] == INF:
print("INFINITY")
else:
print(distances[i])
Python
복사
순차 탐색 다익스트라 알고리즘 성능
시간 복잡도는 O(n^2) 입니다
파이썬 기준으로 1초에 2천만번 연산이 넘어가면 시간 초과가 날 수 있기 때문에 최적화할 여지가 있으면 최적화하는 것이 더 좋습니다

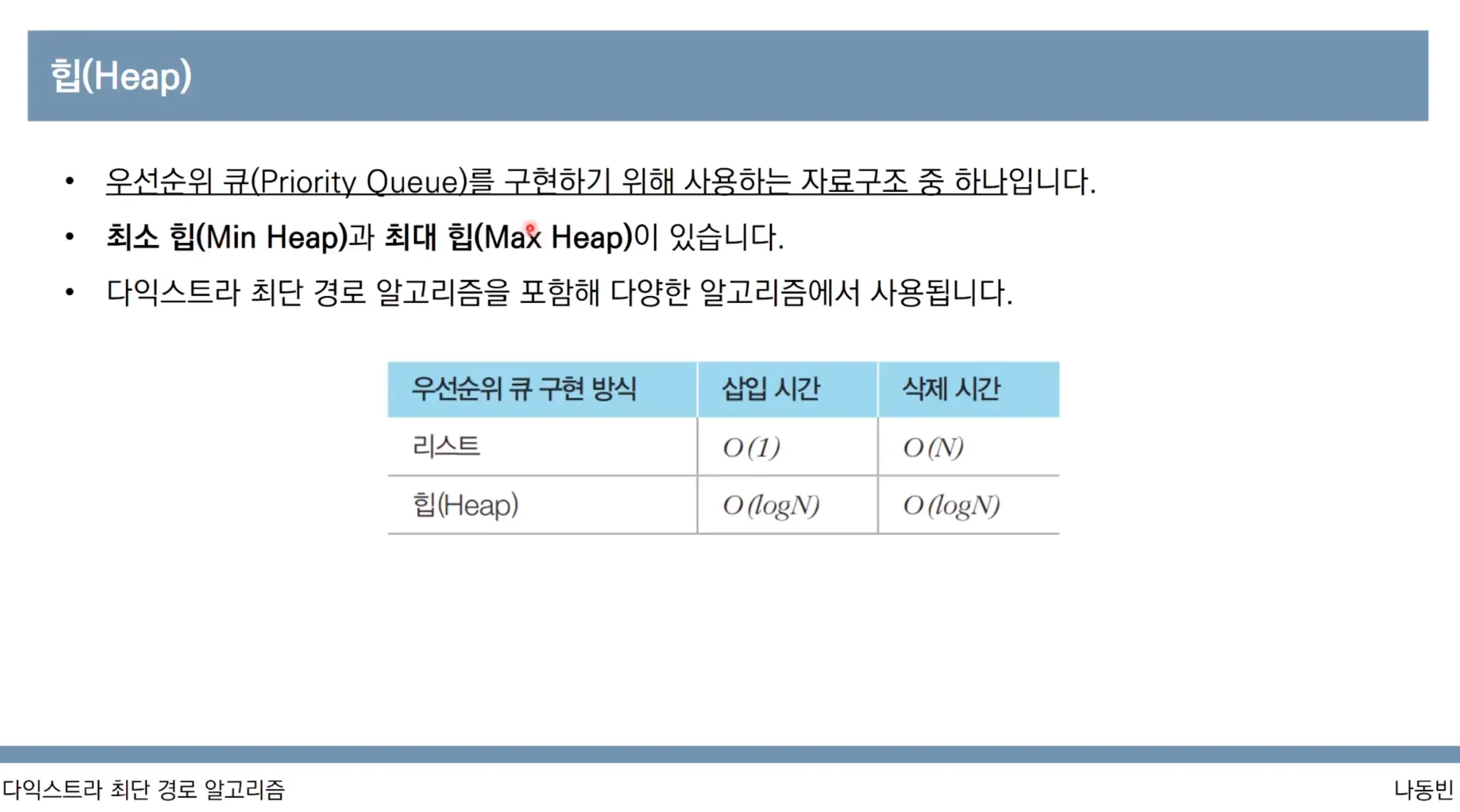
우선순위 큐를 사용하여 더 효율적으로 만들기

•
최소 힙은 값이 낮은 데이터부터 꺼내는 방식으로 동작
•
최대 힙은 값이 높은 데이터부터 꺼내는 방식으로 동작
[최소힙]

[최대힙]
파이썬에서는 따로 최대 힙을 지원하지 않습니다.
부호를 바꾸어서 넣고 뺄 때도 부호를 바꾸어서 꺼냅니다.

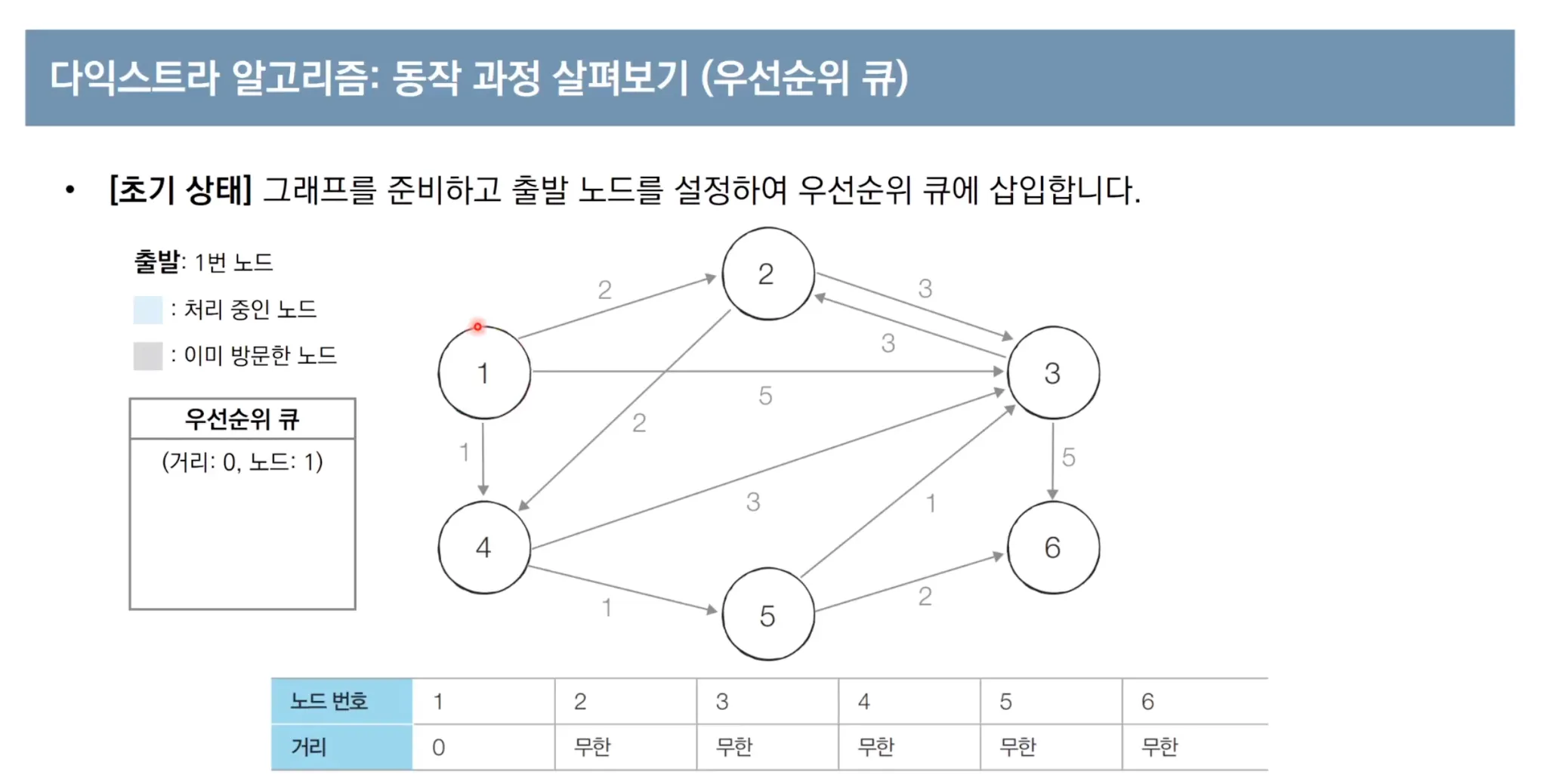
다익스트라에 우선순위 큐(힙)를 사용하여 개선합니다
방문하지 않은 노드 중에서 최단 거리가 가장 짧은 노드를 우선순위 큐에서 탐색하여 탐색시간을 O(logN)으로 줄입니다. 순차 탐색의 경우 O(n)이었습니다.

우선순위 큐를 이용한 다익스트라 알고리즘 동작 과정
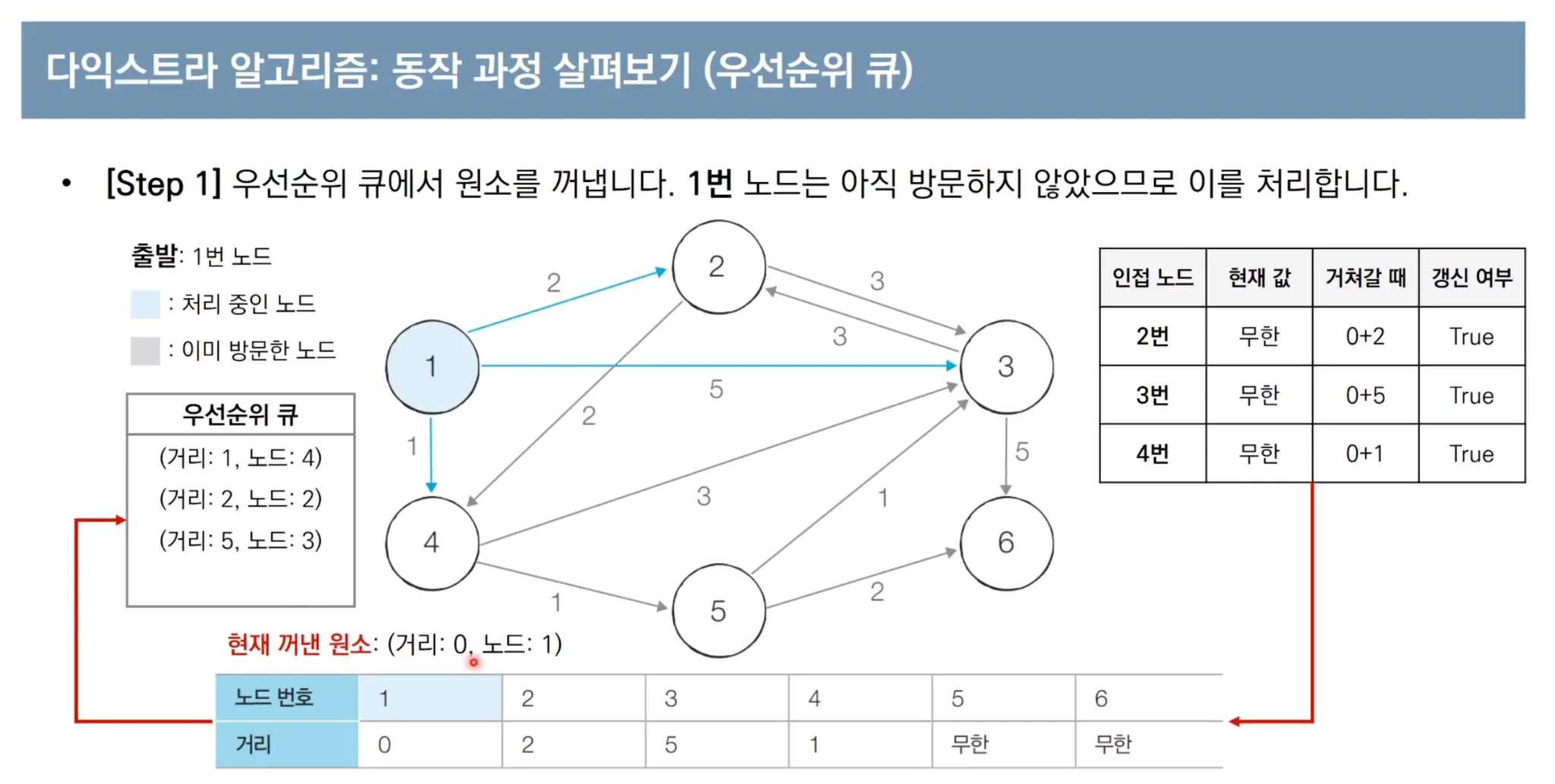
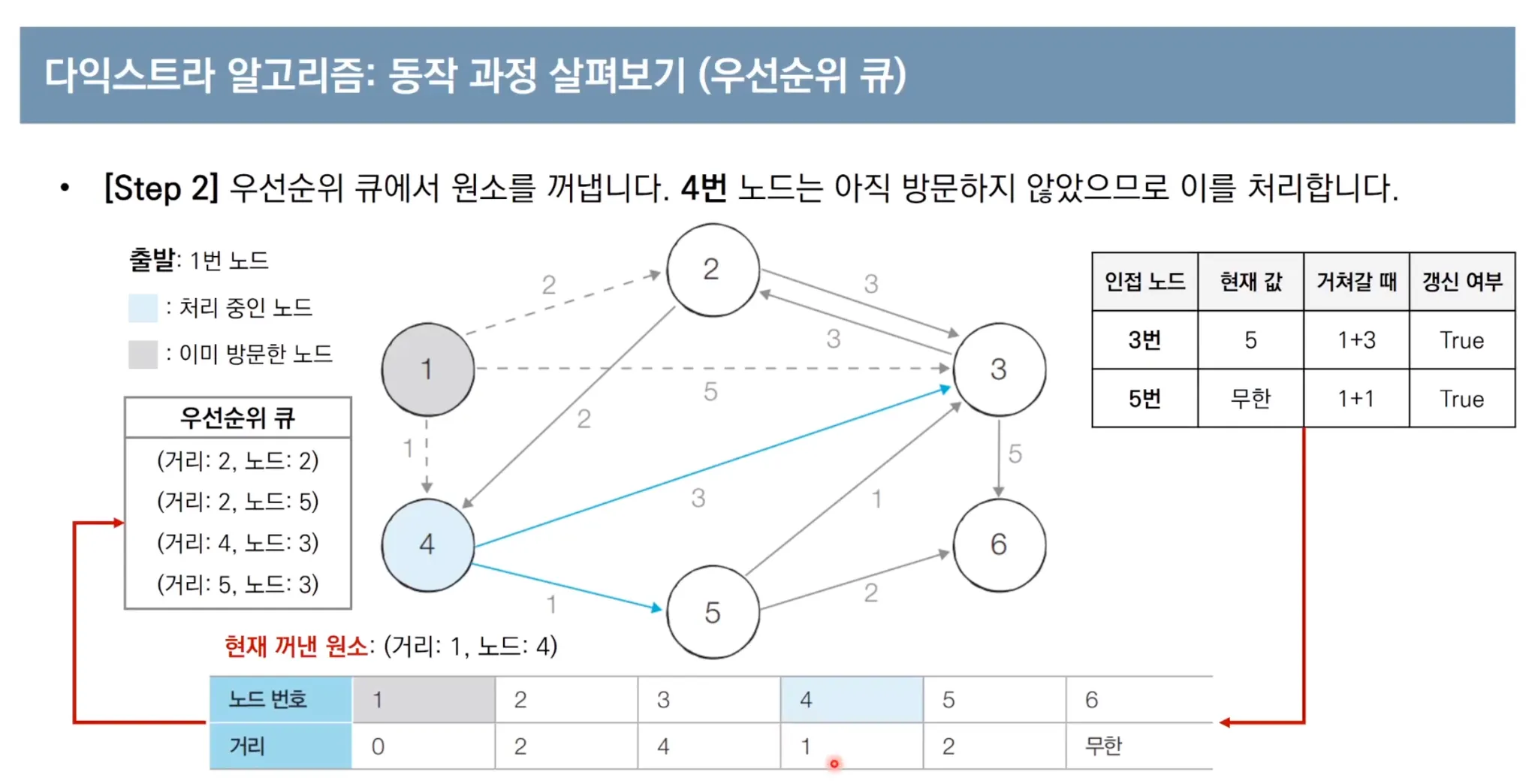
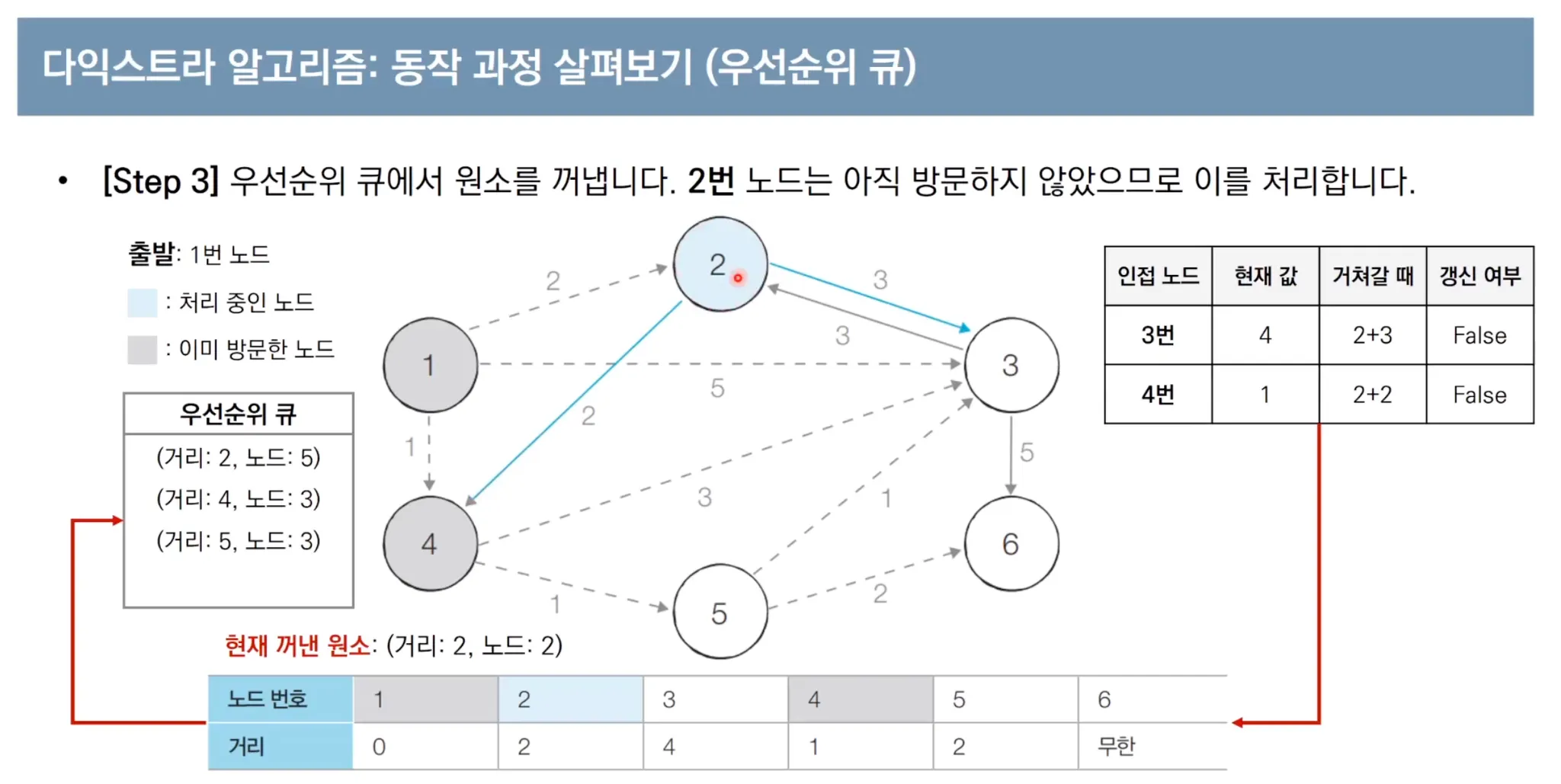
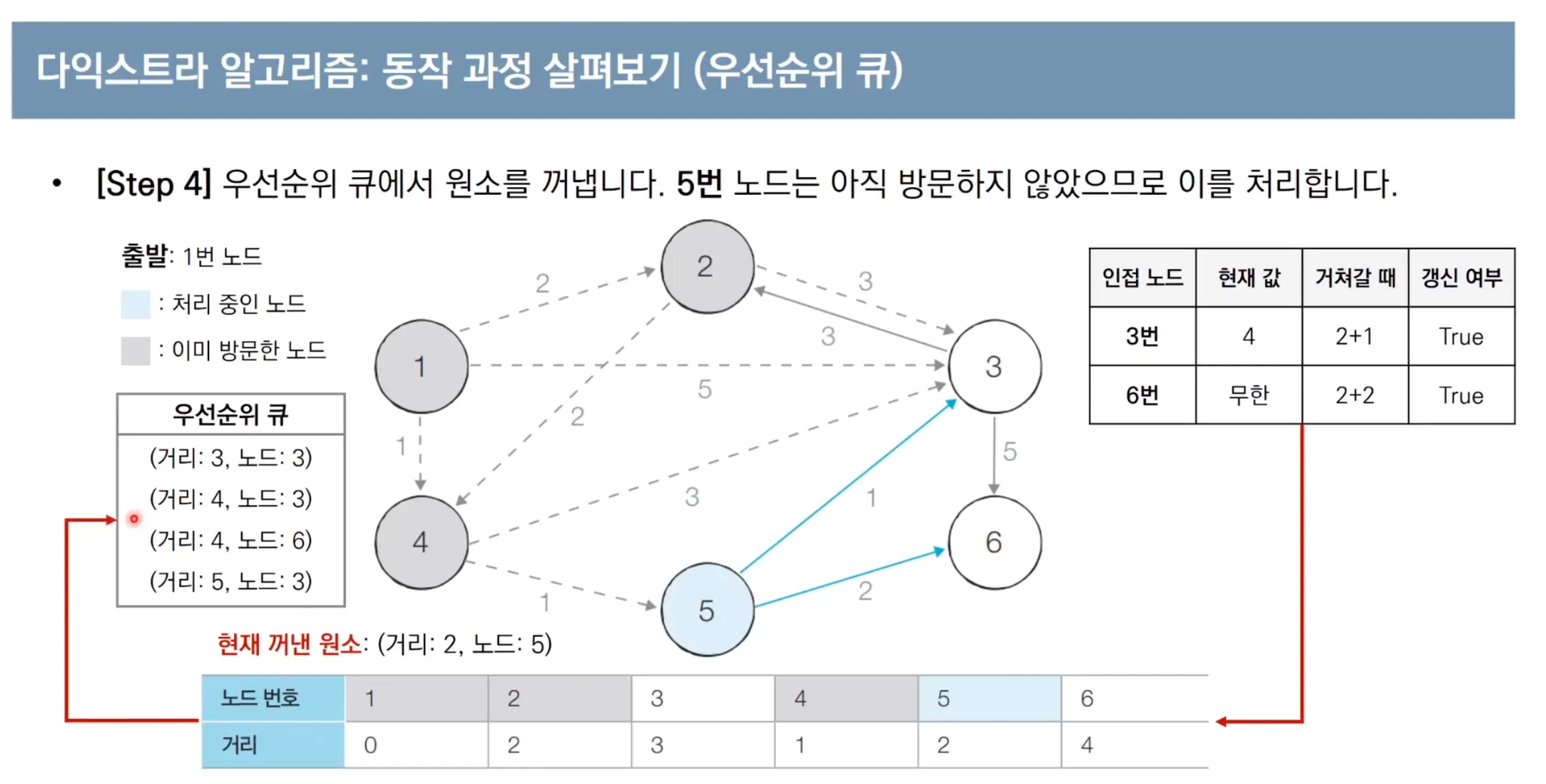
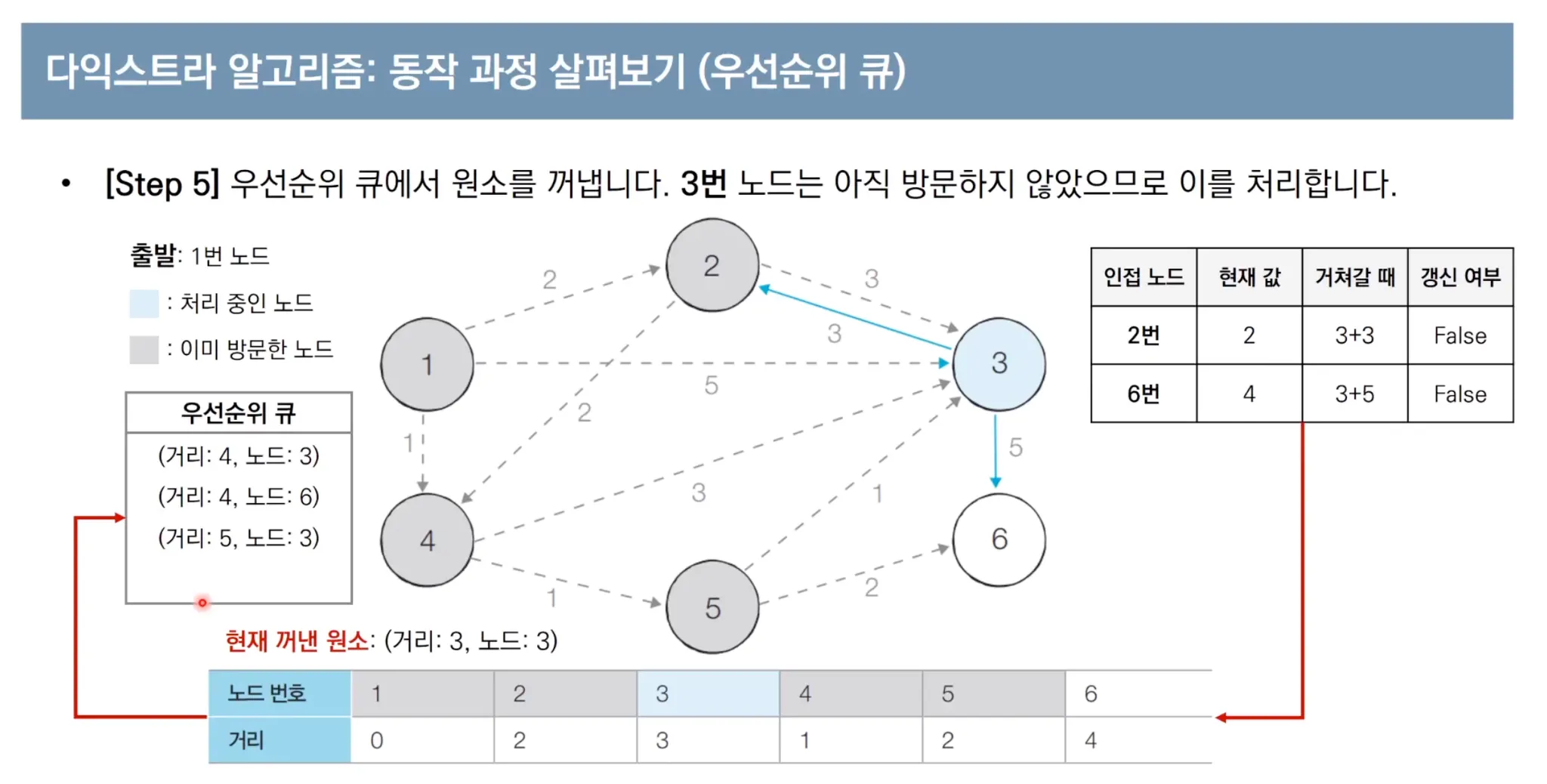
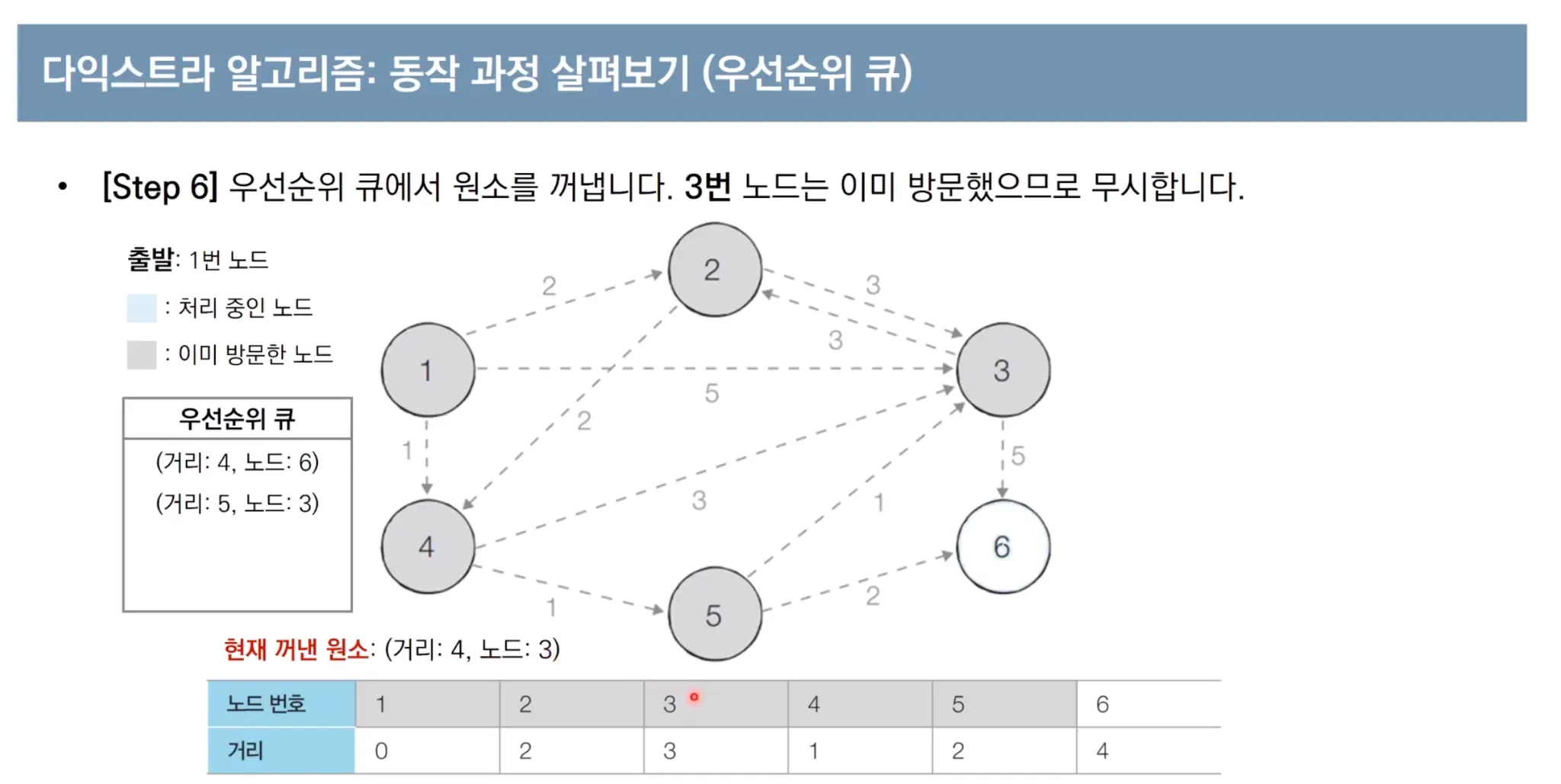
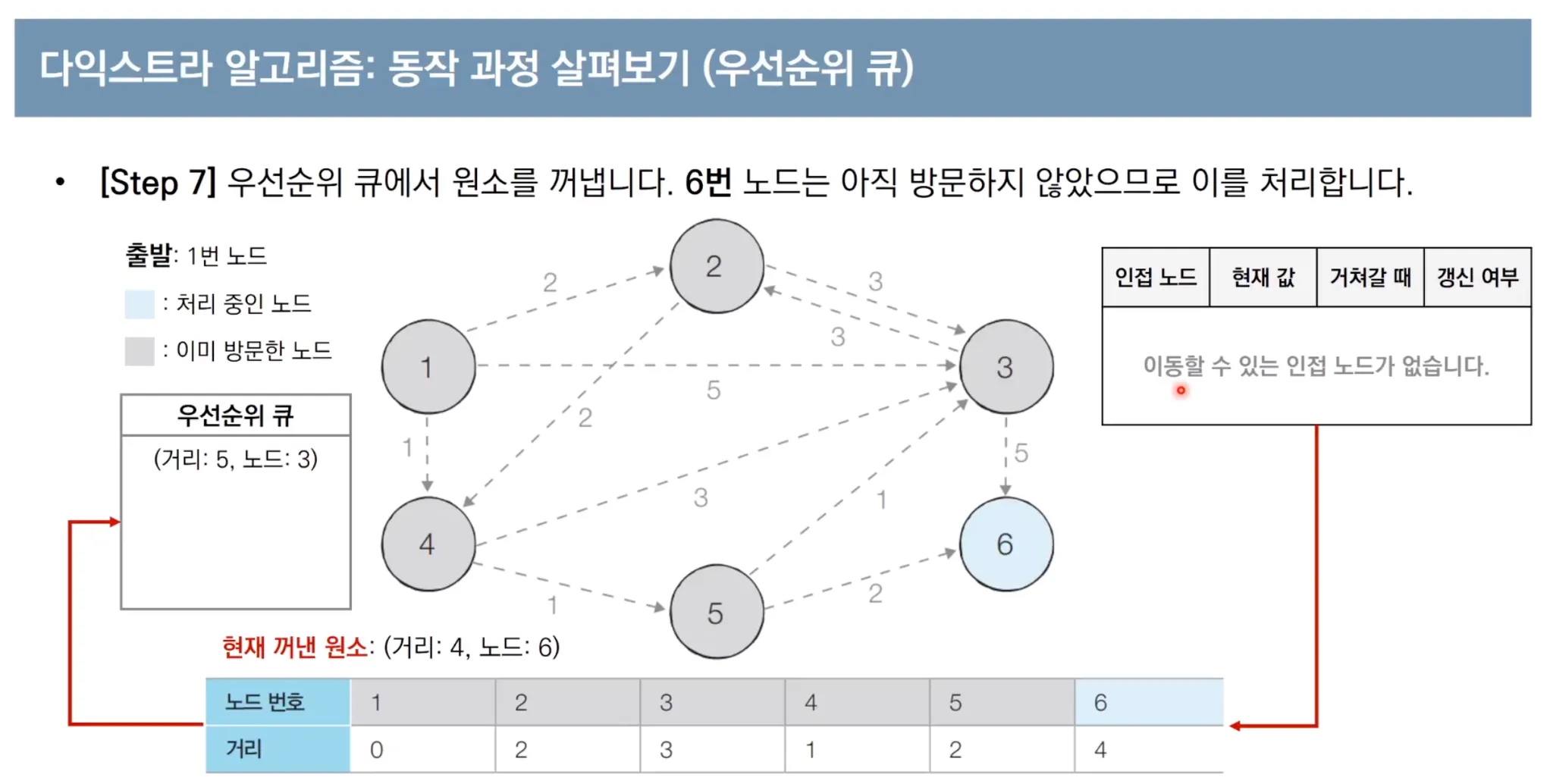
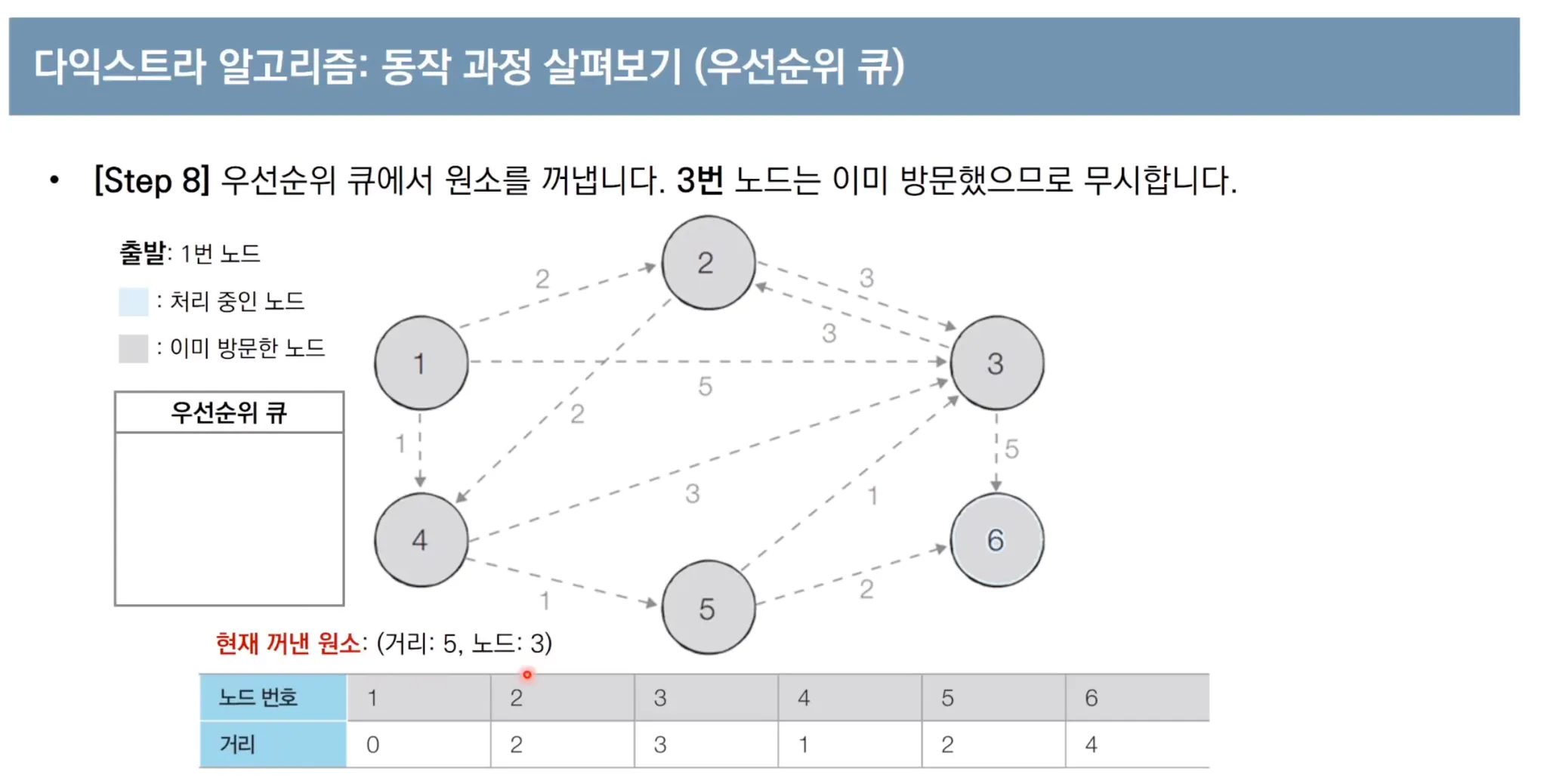
우선순위 큐를 사용한 다익스트라 파이썬 코드
import heapq
import sys
input = sys.stdin.readline
INF = int(1e9)
# 노드의 개수, 간선의 개수를 입력받기
n, m = map(int, input().split())
# 시작 노드 번호를 입력받기
start = int(input())
# 각 노드에 연결되어 있는 노드에 대한 정보를 담는 리스트를 만들기
graph = [[] for _ in range(n + 1)]
# 최단 거리 테이블을 모두 무한으로 초기화
distances = [INF] * (n + 1)
# 모든 간선 정보를 입력받기
for _ in range(m):
a, b, c = map(int, input().split())
# a번 노드에서 b번 노드로 가는 비용이 c
graph[a].append((b, c))
def dijkstra(start):
q = []
# 시작 노드로 가기 위한 최단 거리는 0으로 설정하여, 큐에 삽입
heapq.heappush(q, (0, start))
distances[start] = 0
while q:
# 가장 최단 거리가 짧은 노드에 대한 정보 꺼내기
current_distance, now = heapq.heappop(q)
# 현재 노드가 이미 처리된 적이 있는 노드라면 무시
# visited 리스트를 따로 만들지 않고 이미 처리되었는 지 체크
if distances[now] < current_distance:
continue
# 현재 노드와 연결된 다른 인접한 노드들을 확인
for i in graph[now]:
cost = current_distance + i[1]
# 현재 노드를 거쳐서, 다른 노드로 이동하는 거리가 더 짧은 경우
if cost < distances[i[0]]:
distances[i[0]] = cost
heapq.heappush(q, (cost, i[0]))
# 다익스트라 알고리즘을 수행
dijkstra(start)
# 모든 노드로 가기 위한 최단 거리를 출력
for i in range(1, n + 1):
# 도달할 수 없는 경우, 무한(INF) 출력
if distances[i] == INF:
print("INF")
else:
print(distances[i])
Python
복사
우선순위 큐를 사용한 다익스트라 알고리즘 성능
우선순위 큐(힙)를 사용하여 구현한 다익스트라 알고리즘의 시간 복잡도는 O(N*logN) 입니다
