



CPU의 성능을 향상하는 가장 좋은 방법은 CPU의 클록을 높이거나 캐시의 크기를 늘리는 것이다.
•
그러나 CPU의 클록을 높이면 발열 문제가 있기 때문에 현재의 기술로는 5GHz가 넘는 CPU를 개발하기 어렵다.
•
캐시의 크기를 늘리는 것도 비용 문제가 발목을 잡아 쉽지 않다.
CPU의 핵심 기능을 가진 코어를 여러 개 만들거나, 동시에 실행 가능한 명령의 개수를 늘리는 방법을 사용한다.
병렬 처리의 개념
병렬 처리(Parallel processing)는 동시에 여러 개의 명령을 처리하여 작업의 능률을 올리는 방식을 말한다.
병렬 처리 시 고려 사항
1.
상호 의존성이 없어야 병렬 처리가 가능하다.
•
각 명령이 서로 독립적이고 앞의 결과가 뒤의 명령에 영향을 미치지 않아야 한다는 뜻이다.
2.
각 단계의 시간을 거의 일정하게 맞춰야 병렬 처리가 원만하게 이루어진다.
•
각 단계의 처리 시간이 들쑥날쑥하면 앞의 작업이 먼저 끝나더라도 가장 긴 시간이 걸리는 단계에서 병목 현상이 발생한다.
•
즉 오랜 시간이 걸리는 작업 때문에 진행이 전반적으로 밀려서 전체 작업 시간이 늘어난다.
•
이처럼 단계별 시간의 차이가 크면 병렬 처리의 효과가 떨어진다.
3.
전체 작업 시간을 몇 단계로 나눌지 잘 따져보아야 한다.
a.
병렬 처리에서 작업을 N개로 쪼갰을 때 N을 병렬 처리의 깊이(depth of parallel processing)라고 한다.
b.
병렬 처리의 깊이 N은 동시에 처리할 수 있는 작업의 개수를 의미한다.
c.
N이 커질수록 동시에 작업할 수 있는 작업의 개수가 많아져서 성능이 높아질 것이다.
d.
하지만 작업을 너무 많이 나누면 각 단계마다 작업을 이동하고 새로운 작업을 불러오는 데 시간이 너무 많이 걸려서 오히려 성능이 떨어진다. 이러한 오버헤드를 고려하여 보통은 병렬 처리의 깊이를 10~20 정도로 한다.
병렬 처리 기법
CPU 내에서 명령어는 제어장치가 처리한다.
•
제어장치는 명령어를 가져와 해석한 후 실행하고 결과를 저장하는 과정을 계속 반복한다.
•
이러한 과정 전체를 하나의 스레드라고 하며,
•
스레드를 이루는 각 단계는 CPU의 클록과 연동되어 한 클록에 한 번씩 이루어진다.
CPU에서 명령어가 실행되는 과정
1.
명령어 패치(Instruction Fetch. IF): 다음에 실행할 명령어를 명령어 레지스터에 저장한다.
2.
명령어 해석(Instruction Decode. ID): 명령어를 해석한다.
3.
실행(Execution. EX): 해석한 결과를 토대로 명령어를 실행한다.
4.
쓰기(Write Back. WB): 실행된 결과를 메모리에 저장한다.
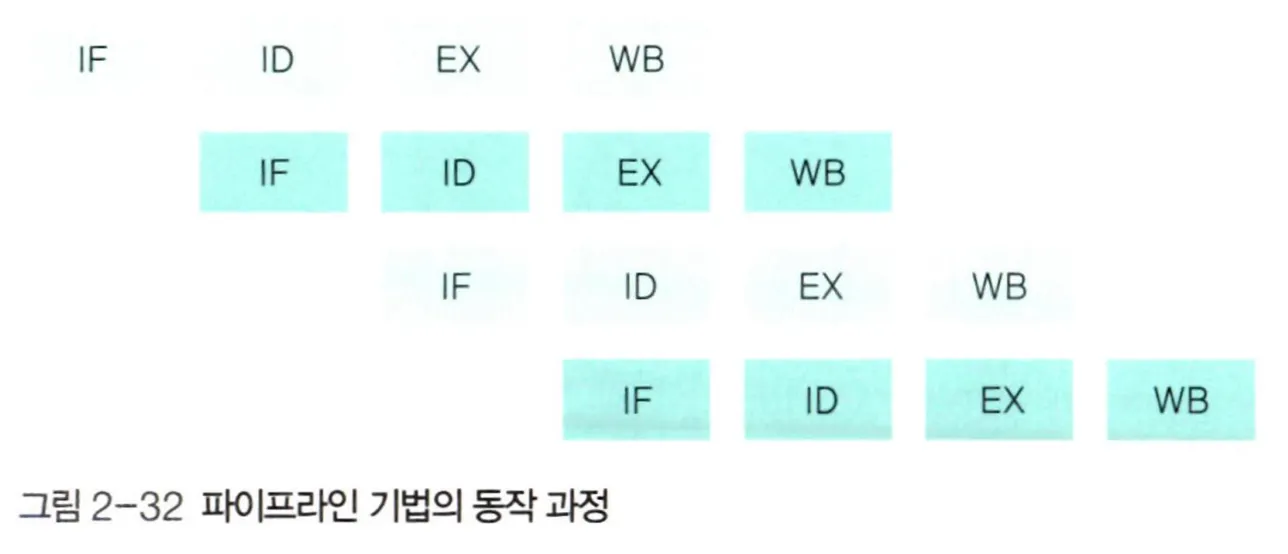
파이프라인 기법
파이프라인(pipeline) 기법은 명령을 겹쳐서 실행하는 방법으로, CPU의 사양과 연관지어 보면 하나의 코어에 여러 개의 스레드를 사용하는 것이다.
명령어를 여러 개의 단계로 분할한 후, 각 단계를 동시에 처리하는 하드웨어를 독립적으로 구성한다.
파이프라인의 위험
1.
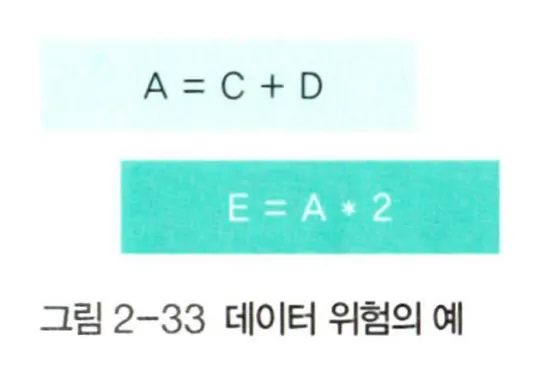
데이터 위험
•
데이터 위험(data hazard)은 데이터의 의존성 때문에 발생하는 문제이다.
•
데이터 A를 필요로 하는 두 번째 명령어는 앞의 명령어가 끝날 때까지 동시에 실행되어서는 안 된다.
•
데이터 위험은 파이프라인의 명령어 단계를 지연하여 해결한다.
2.
제어 위험

•
분기를 하는 if 문 혹은 바로가기의 goto 문 같은 명령에서 발생하는 제어 위험(control hazard)은 프로그램 카운터 값을 갑자기 변화시켜 발생하는 위험이다.
•
첫 명령어를 실행하고 보니 goto 문이어서 다음 문장이 아니라 다른 문장으로 이동 하게 되면 현재 동시에 처리되고 있는 명령어들이 쓸모없어진다.
•
제어 위험은 분기 예측이나 분기 지연 방법으로 해결한다.
3.
구조 위험
•
구조 위험(structural hazard)은 서로 다른 명령어가 같은 자원에 접근하려 할 때 발생하는 문제이다.
•
예를 들어 명령어 A가 레지스터 RX를 사용하고 있는데 병렬 처리되는 명령어 B도 레지스터 RX를 사용해야 한다면 서로 충돌하게 된다.
•
이러한 구조 위험은 해결하기 어렵다고 알려져 있다.
파이프라인 기법을 인텔 계열의 CPU에서는 하이퍼스레드라고 부른다.
하이퍼스레드는 CPU에 여러 개의 작업을 동시에 진행할 수 있는 부가장치를 만들어 하나의 코어에서도 여러 개의 작업(스레드)이 동시에 이루어지게 하는 기법이다.
슈퍼스칼라 기법
슈퍼스칼라(super-scalar) 기법은 파이프라인을 처리할 수 있는 코어를 여러 개 구성하여 복수의 명령어가 동시에 실행되도록 하는 방식이다.
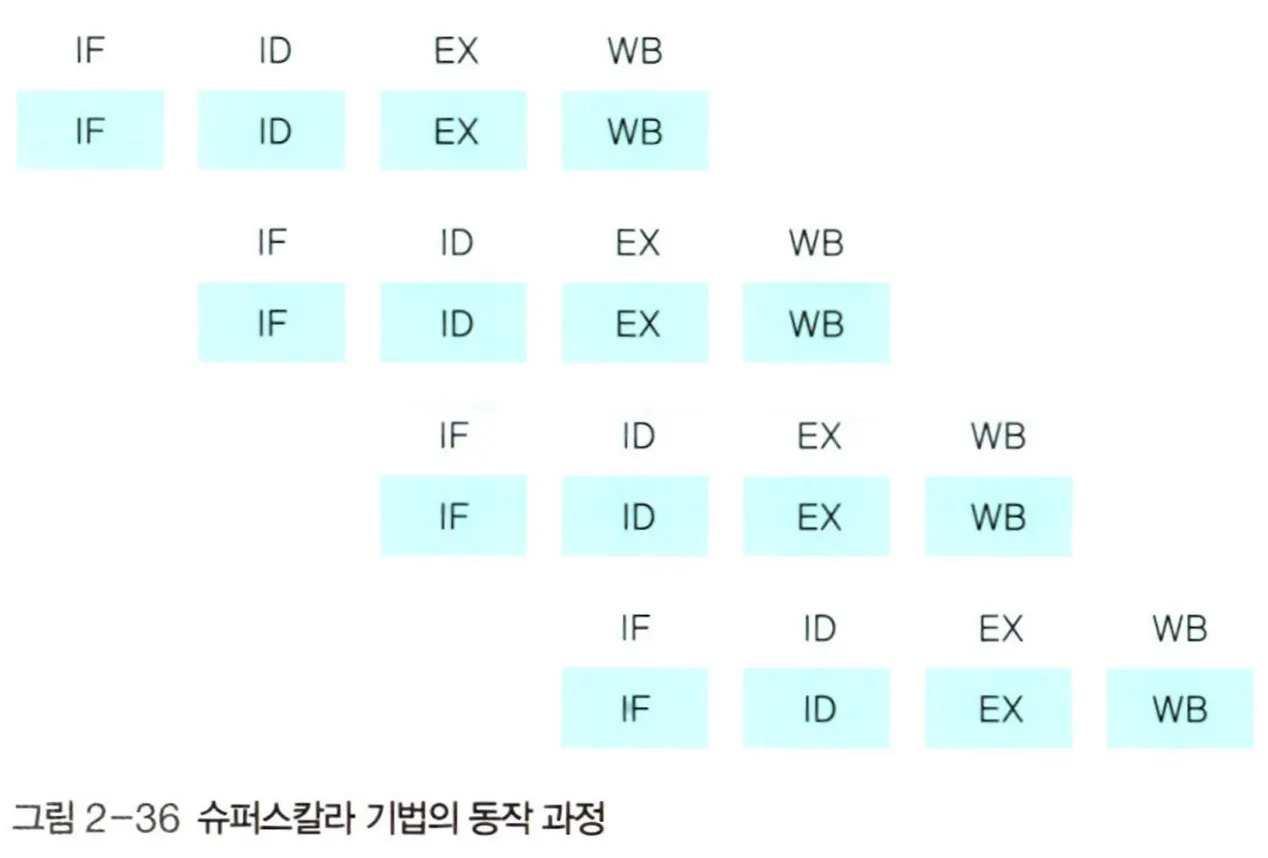
대부분은 파이프라인 기법과 동일하지만 코어를 2개 구성하여 각 단계에서 동시에 실행되는 명령어가 2개라는 점이 다르다. 이 경우 전체적으로 동시에 실행되는 명령어의 개수는 8개이다.
파이프라인 기법과 마찬가지로 슈퍼스칼라 기법에서는 처리되는 명령어가 상호 의존성 없이 독립적이어야 하며, 이를 위한 처리도 컴파일러에서 이루어지도록 조정해야 한다.
VLIW 기법
앞의 병렬 처리 기법들은 병렬 처리를 지원하는 하드웨어적인 방법이지만, VLIW(Very Long Instruction Word) 기법은 CPU가 병렬 처리를 지원하지 않을 경우 소프트웨어적으로 병렬 처리를 하는 방법이다.
VLIW 기법에서는 동시에 수행할 수 있는 명령어들을 컴파일러가 추출하고 하나의 명령어로 압축하여 실행한다.
VLIW 기법은 CPU가 병렬 처리를 지원하지 않을 때 사용하는 방법이므 로 앞의 병렬 처리 기법들에 비해 동시에 처리하는 명령어의 개수가 적다. 또한 앞의 병렬 처리 기법들은 명령어 실행 시 병렬 처리가 이루어지지만 VLIW 기법은 컴파일 시 병렬 처리가 이루어진다.